Over the last month or so I’ve been involved in some consultancy work for the Evening Standard. The task was to develop a map to communicate the extension of the newspaper’s distribution network, a plan that was announced on their website and went into action last week.
The work involved the production of three maps, reflecting the current, new and combined distribution networks.
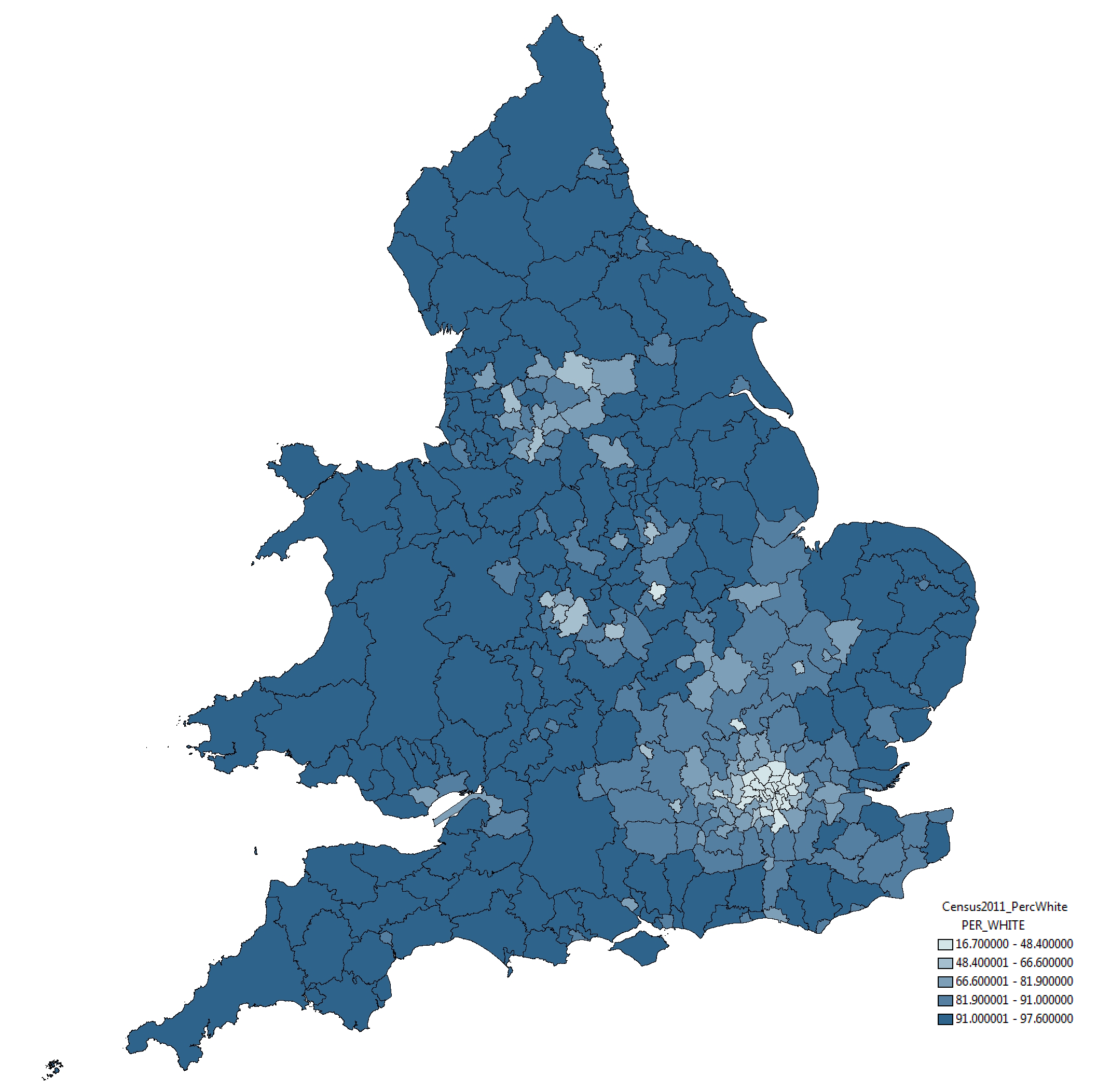
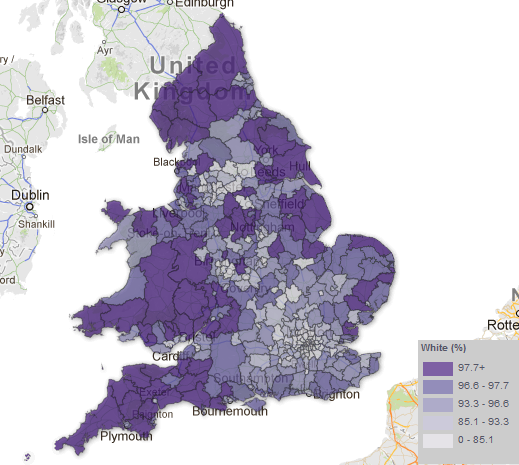
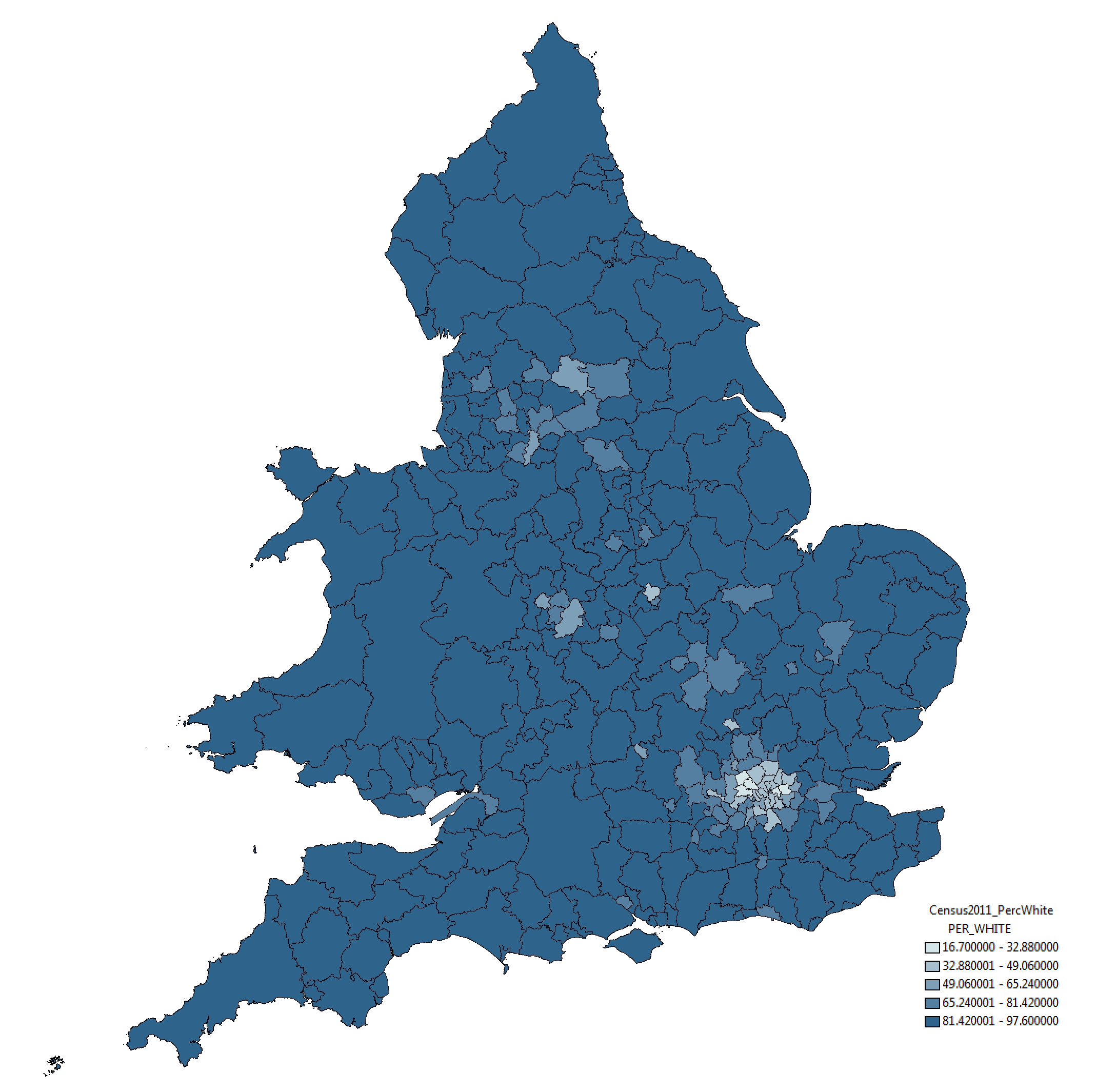
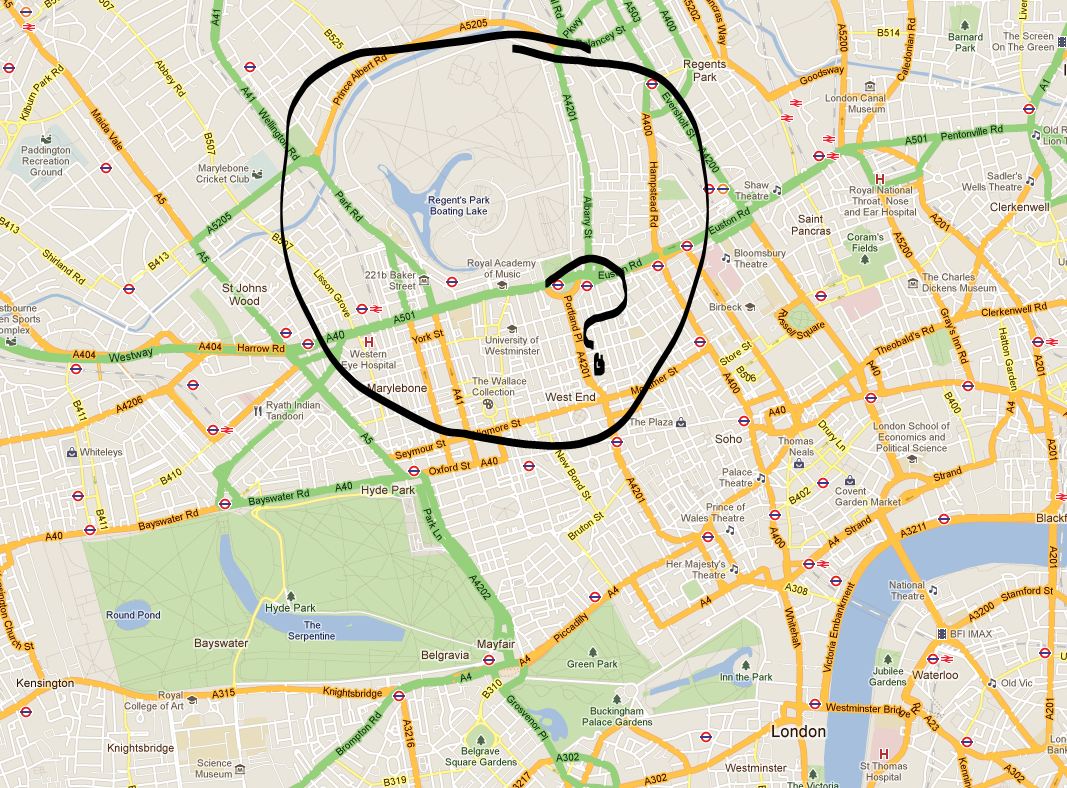
Each map includes a considerable amount of metadata, providing contextual support for the expansion. I’ve drawn most of these from OpenStreetMap, however, the Evening Standard also requested an indication of the boundaries of the first six transport charging zones, a dataset that doesn’t otherwise exist. The London transport zones are used by Transport for London as a charging mechanism on the Underground and rail network associated with stations only, but have no strictly geographical extent.
For those that are interested, the methodology I applied was quite straightforward. In the first instance, I constructed a set of polygons bounded at the extents of the outer station in each zone. Following this, I generalised the edges of each polygon using Bézier Curves, smoothing the edges of the polygon. The whole process required a bit of artistic licence to control the curves from overlapping erroneously, but for the most part the methodology is reproducible (should you feel so inclined).
Without any further ado, here is the map of the proposed changes. This map focuses on the expansion rather than the existing distribution, with the size and colour of each point reflecting the proportion of the expanded supply shared across each location. The existing distribution points are included for context, and do effectively demonstrate the big logistical challenge they are taking on.
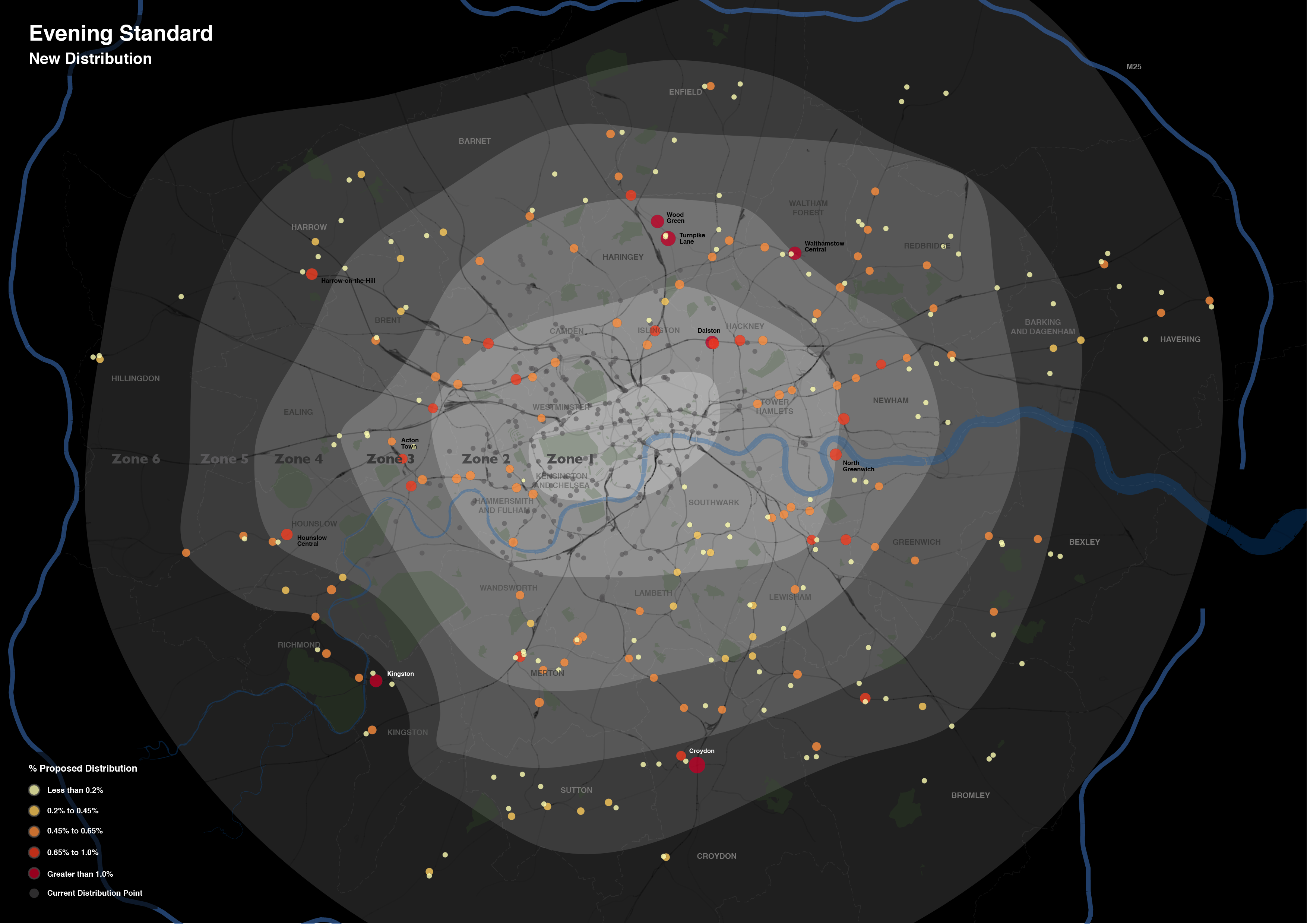
What is interesting is the spatial extent of the expansion. Whereas previously the distribution of the newspaper was focussed around central London Tube stations, the expansion takes the paper out into the suburbs. I don’t know for sure, but one assumes that is a move to get the paper into reader’s homes. As the Standard is a free newspaper, people may read it on their Tube ride home but then discard it. If someone is able to pick it up on the other side of their journey home, then they might not be so tempted to pick up another rival newspaper instead. At least that’s one possible explanation.
In the end the client was very satisfied with the results, but don’t take my word for it, you can read about their views at this blog post on the UCL Consultants website.
Now, if you’re impressed with this map, and have an important mapping task that can only be left at the hands of a true professional, then get in touch! Like the Evening Standard did, I am hireable as a UCL Consultant, just drop me a line using the details on the Contacts page.