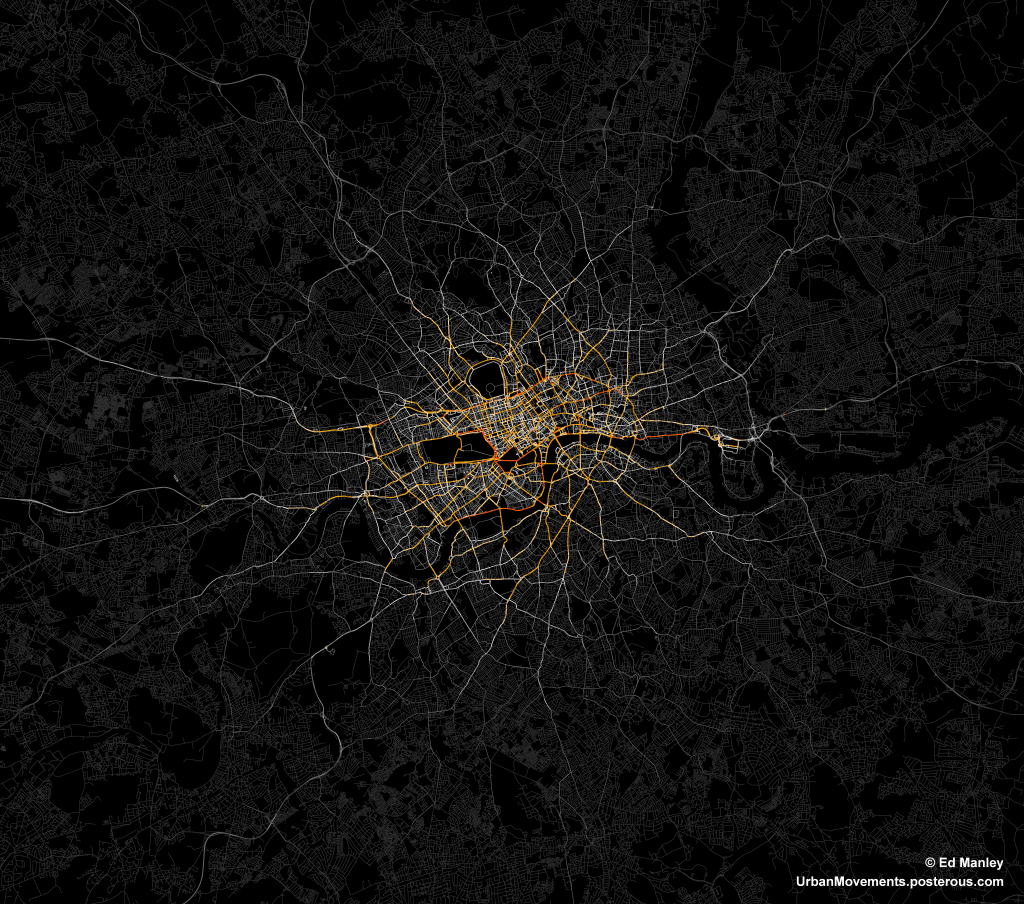
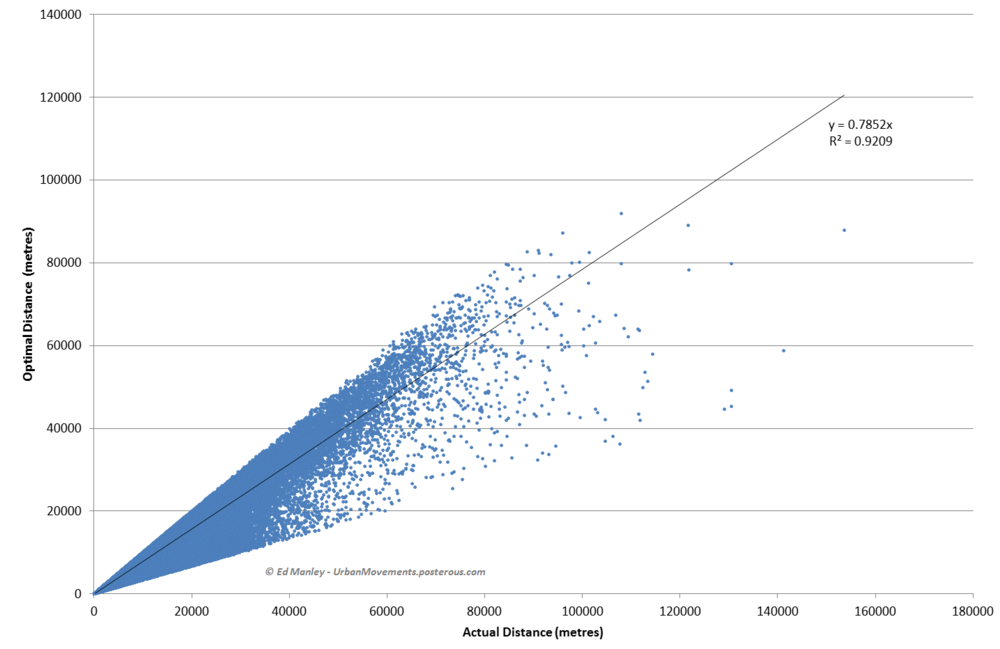
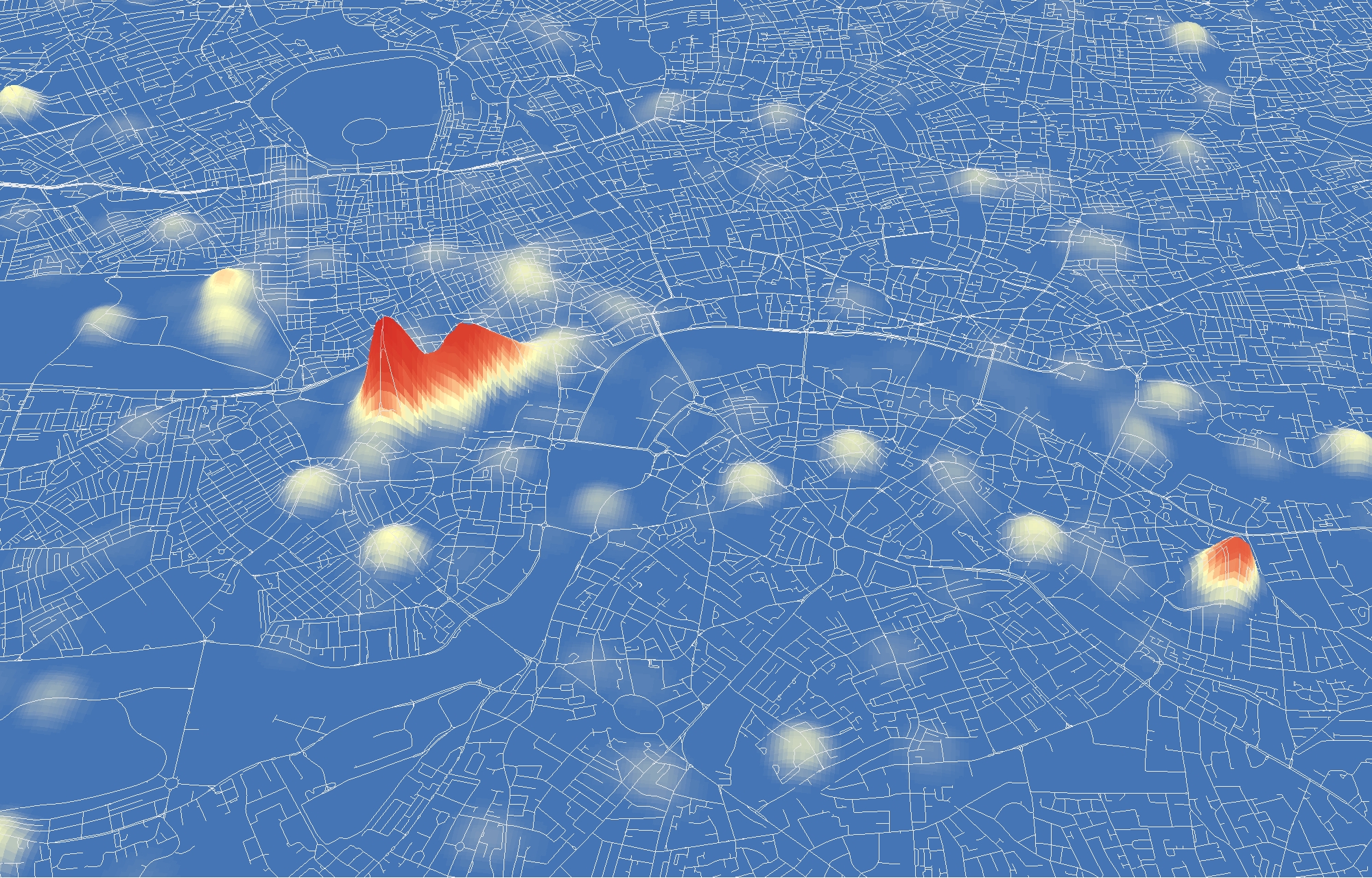
One of the biggest advantages, I feel, about studying urban transport phenomena in London is the simple ability to be able look out of the window and see what is actually going on. This week, the Olympics and its (supposed) transportation chaos, came to London.
What has struck me early on, mainly since the introduction of the Games Lanes last week, is a big reduction in the number of vehicles on the road. There have been reports of certain inevitable problems in various parts of the capital, but my experience has been a general reduction in demand on most roads (see a couple of photos I took below). This sentiment has been shared by a number of my colleagues. There has been no word yet from Transport for London as to whether the data is backing this up.

Second, the big public transport problems predicted at certain stations and at certain times, have no yet come to fruition. Warnings were issued widely this morning about potential overcrowding at a number of stations, yet early reports suggest that this is far from the reality – the Guardian highlight a number of citizen reports of empty Tube seats and quiet stations this morning.

Typical fear-inducing GetAheadOfTheGames literature (copyright Transport for London 2012)
It appears that the strategy has worked. In fact, one might even suggest that it has worked better than expected. I would say that this is partly down to the impact of irrationality, specifically the impact of fear. Individuals, scared of potentially having to wait considerable amounts of time at stations only to cram into packed Tube trains, or fearful of long queues on the roads, have changed their habitual plans en masse.
Social Phenomena
The effect has gone to demonstrate, at least to me, the impact that small changes in the behaviour of many individuals can have on the nature of the city. As individuals, we make a choice, we carry out that action, and we are mostly unaware of the impact that decision has on shaping broader phenomena. Yet, in observing the patterns these many individuals make, we can begin to see how individual and social attitudes impact on shaping transportation flows.
This relationship, specifically the impact that fear has had in the context of the Olympics, appears to have caught some analysts on the hop. INRIX, a big transport data provider, predicted earlier in the year the ‘perfect traffic storm‘ in traffic demand during the first few days of the Games (reported in more detail here). This patently failed to happen. The models INRIX employed in making these predictions clearly failed to make consideration for the impact that fear would play in reducing traffic demand. This approach is far from uncommon where transport demand modelling is concerned.
The Games have a long way to run yet, and we may well see a counter movement occur in time as people begin to realise that transportation isn’t as bad as first expected. But I think the impact that fear has held on shaping, at least, the first few days of transportation flows makes for interesting viewing.