As it’s been a while since I last posted, I thought I’d put up something I prepared for a Royal Society Smart Cities and Transportation workshop next week. I’ve focussed on data collected at the individual-level, and the opportunities the data present for better understanding cities, and the challenges the maximisation of these resources face. There are no doubt alternative perspectives, arguments that go deeper beyond this very short piece, and methodological issues too to contend with. Feel free to add your thoughts in the comments at the end.
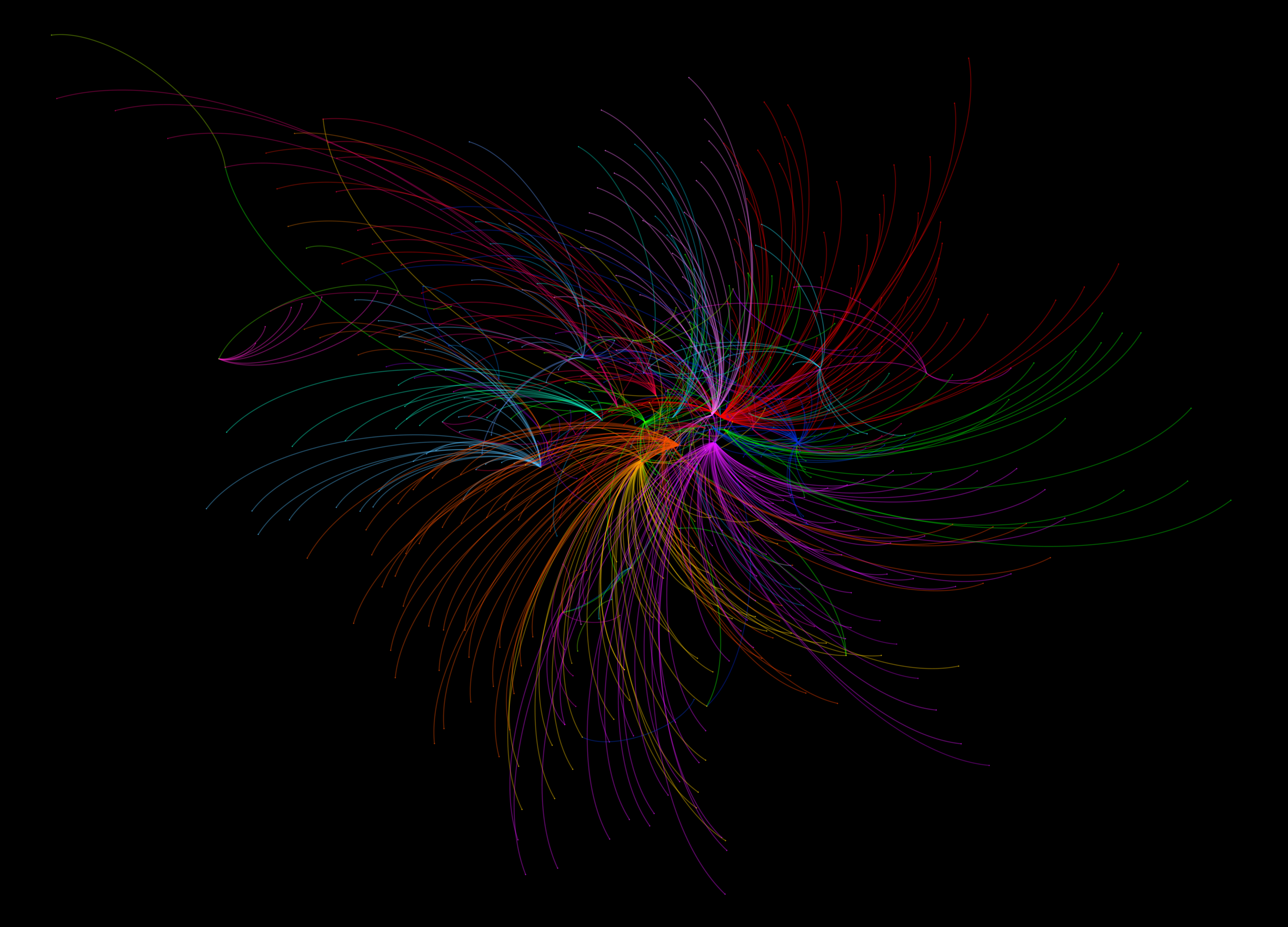
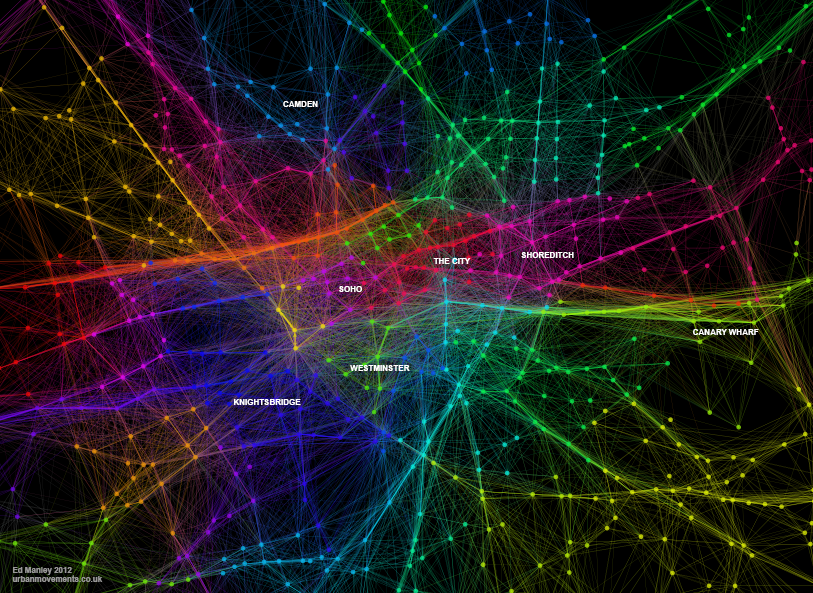
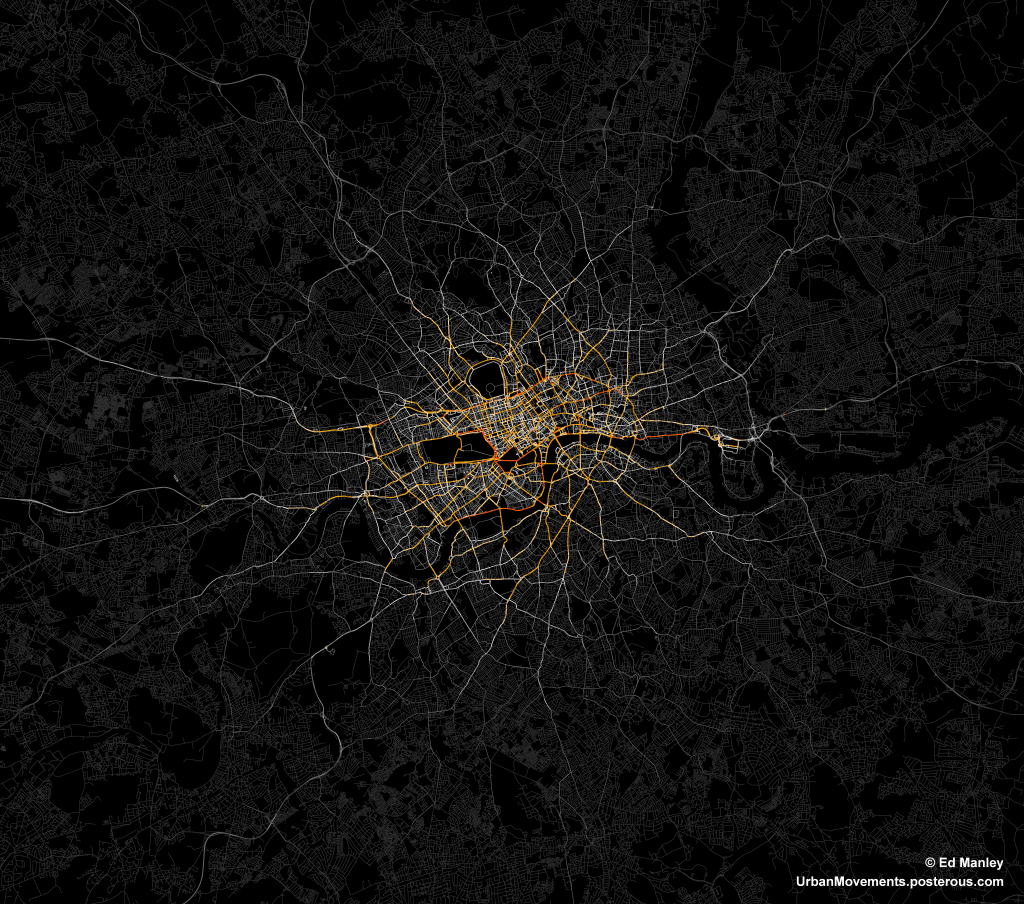
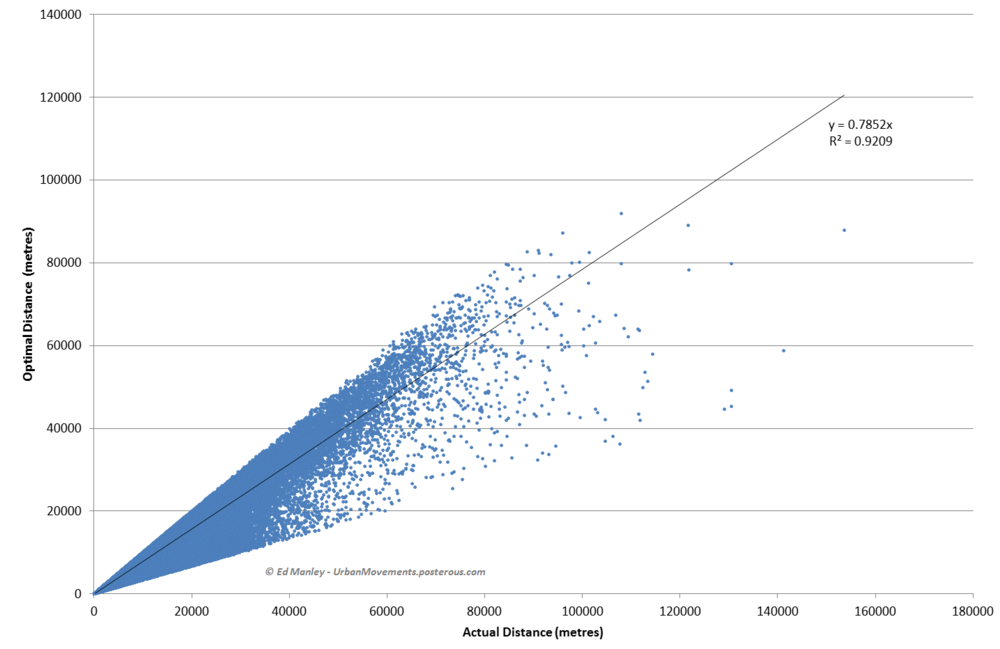
As the creation, capture and accumulation of granular datasets becomes increasingly engrained within the urban environment, the potential for analysing urban processes in finer and finer detail increases. New forms of data are being generated at spatial, temporal and individual-level scales that surpass all that have gone before. These data transcend the boundaries that previously imposed on analyses of cities – traffic flow can be captured on a second-by-second basis road-by-road, crime incidents are habitually recorded with a longitude and latitude, and commuting patterns can be captured live through the movements of mobile phones. Through the development of a wealth of new methods, machine learning approaches are able to derive deeper insight from these data, revealing new patterns and understanding of cities than have been available before. It is, however, increasing granularity individual behaviours that offers the greatest promise, and poses the biggest challenges for future urban data analysis.
Data derived insights around the individual offer a chance to better understand the behavioural heterogeneity within the population across a range of domains, as well as revealing the complex interconnectivity of urban systems. Capturing these details at finer level could allow us to better measure and model cities, allowing us to improve our current conceptions on how we understand, manage and organise our cities.
The opportunities presented by individual-level analyses are plentiful. Longitudinal data allow us to learn how individuals adjust behaviour over different periods of time and under different conditions, and how they adapt to longer-term changes to the city. Within domains such as transportation, conventional models lack strong behavioural insights, failing to capture behavioural heterogeneity or measure how individual experiences and perceptions influence behaviour. The new lessons we can potentially learn from these data can not only aid our longer term models of urban futures, but contribute towards our management of cities on a day-to-day basis.
The individual-oriented nature of these analyses are able to transcend disciplinary boundaries through which cities have previously been understood and managed. At present, we lack a deep knowledge around the integration of different urban systems, and the influence of the urban realm upon these connections. We might, for example, be interested in the influence of travel on shopping behaviour, or on health, or crime patterns, but the potential interconnections extend far and wide. While conventional surveys provide good localised insight into these behaviours and systems, only through large scale data collection can these interconnectivities be observed across the whole population and entire urban area. The improved understanding of the people and systems that make up the urban realm offers considerable potential for those operating and optimising cities.
Despite the promise, there are considerable challenges to capitalising on these opportunities – underlined primarily by the fact that many of the datasets that could advance our understanding of cities already exist. At the individual scale, longitudinal travel behaviour can be captured by smart card transactions, many retail transactions are captured via loyalty cards, and mobile phones tracked from cell tower to cell tower. There is, however, little opportunity for joined up thinking, as many of these datasets exist within silos, accessible to interested parties only in exchange for a considerable fee. The potential for asking new questions, discovering new insights, and crossing urban systems and disciplines is restricted by commercial confidentiality. Crossing these boundaries requires leadership and openness from business and government, where too often, siloed within their own priorities, perspectives and worldview, a wider vision or motivation for an improved city is lacking.
Beyond structural challenges, however, there are questions of morality, and how far data collection and analysis should be deployed for the purpose of urban development. When one starts to generate data at the individual level, the risk of de-anonymising individuals becomes very real. Data analysts have already proven this in various contexts, using datasets cleared for public release – from the identification of individuals from the movements of their mobile phones, to the identification Netflix users from their viewing habits, to establishing whether celebrities tipped their taxi driver or not. These analyses may have been conducted for benign reasons, but they illustrate the point that the opportunities for revealing identities from data traces sharply increase as data collection reaches individual-level granularity. The questions therefore become how far should these analyses extend, what constraints (if any) should be placed on data collection and analysis to ensure anonymity, and how should methods and results be communicated to the public. At present, there is little guidance from government and seemingly little leadership beyond. Without due consideration given to the treatment of these issues, there is a risk that public trust in data collectors and analysts will be eroded, risking the imposition of limiting constraints on how these data are exploited in future.