
Following the interest in our Twitter language map of London a few months back, James Cheshire and I have been working on expanding our horizons a bit. This time teaming up with John Barratt at Trendsmap, our new map looks at the Twitter languages of New York, New York! This time mapping 8.5 million tweets, captured between January 2010 and February 2013.
Without further ado, here is the map. You can also find a fully zoomable, interactive version at ny.spatial.ly, courtesy of the technical wizardry of Ollie O’Brien.
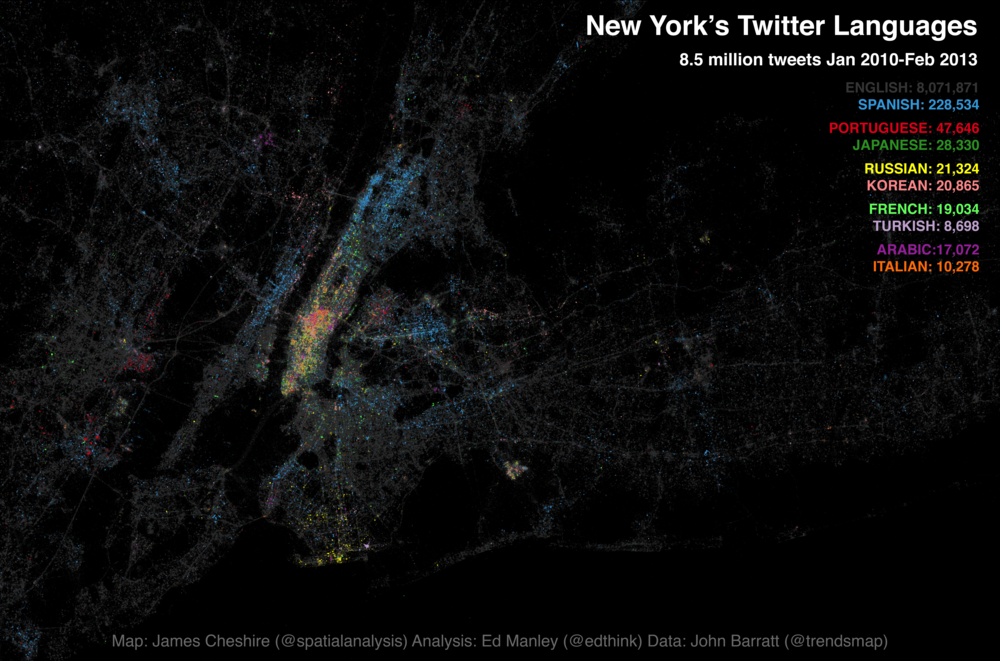
James has blogged over on Spatial Analysis about the map creation process and highlighted some of the predominant trends observed on the map. What I thought I’d do is have a bit more of a deeper look into the underlying language trends, to see if slightly different visualisation techniques provide us with any alternative insight, and the data handling process.
Spatial Patterns of Language Density
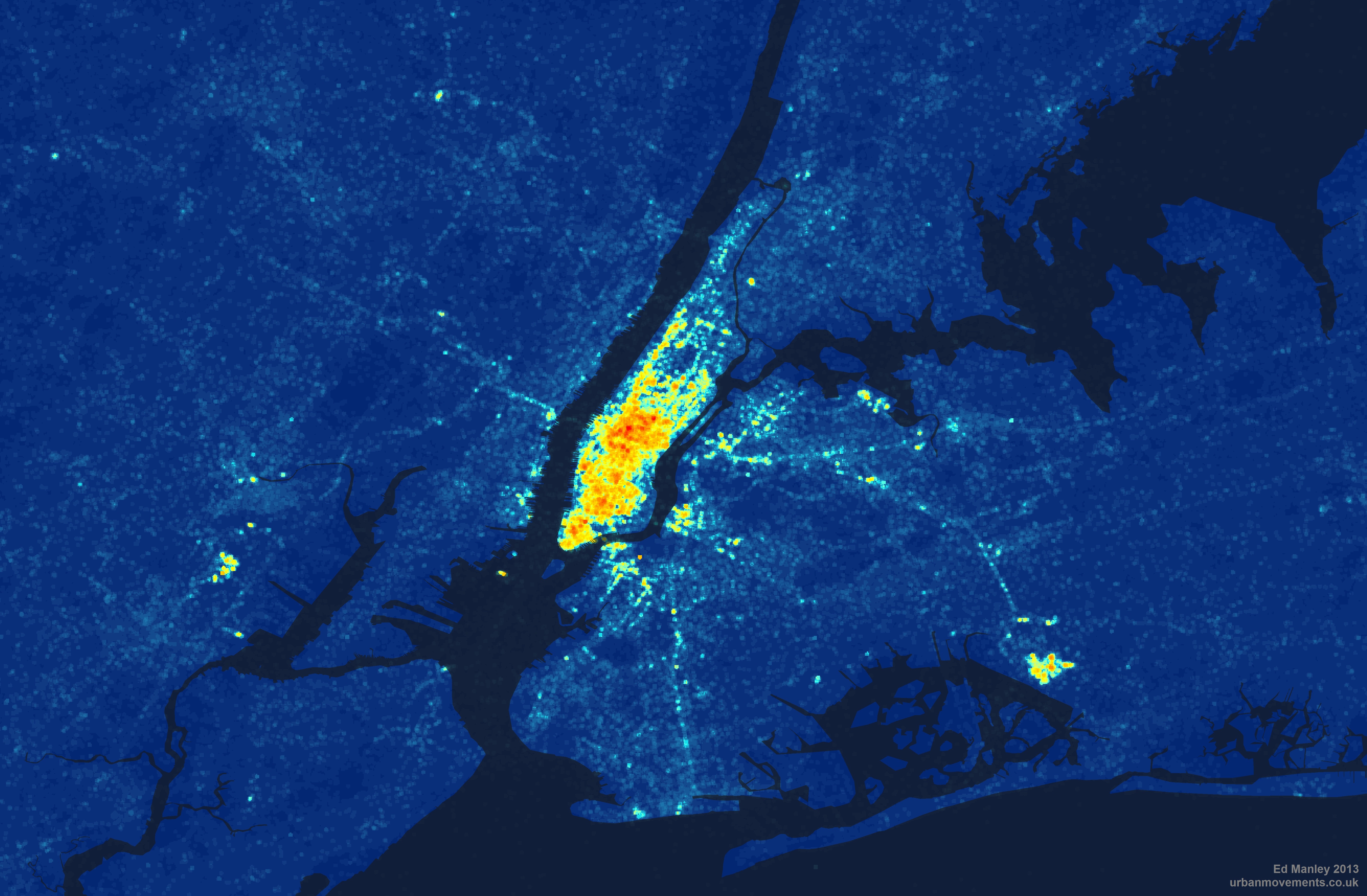
Further to the map, I’ve had a more in-depth look at how tweet density and multilingualism varies spatially across New York. Breaking New York down into points every 50 metres, I wrote a simple script (using Java and Geotools) that analysed tweet patterns within a 100 metre radius of each point. These point summaries are then converted in a raster image – a collection of grid squares – to provide an alternative representation of spatial variation in tweeting behaviour.
Looking at pure tweet density to begin with, we take all languages into consideration. From this map it is immediately clear how Manhattan dominates as the centre for Twitter activity in New York. Yet we can also see how tweeting is far from constrained to this area, spreading out to areas of Brooklyn, Jersey City and Newark. By contrast, little Twitter activity is found in areas like Staten Island and Yonkers.

Density of tweets per grid square (Coastline courtesy of ORNL)
By the same token, we can look at how multilingualism varies across New York, by identifying the number of languages within each grid square. And we actually get a slightly different pattern. Manhattan dominates again, but with a particularly high concentration in multilingualism around the Theatre District and Times Square – predominantly tourists, one presumes. Other areas, where tweet density is otherwise high – such as Newark, Jersey City and the Bronx – see a big drop off where it comes to the pure number of languages being spoken.
Finally, taking this a little bit further, we can look at how multilingualism varies with respect to English language tweets. Mapping the percentage of non-English tweets per grid square, we begin to get a sense of the areas of New York less dominated by the English language, and remove the influence of simply tweet density. The most prominent locations, according to this measure, are now shown to be South Brooklyn, Coney Island, Jackson Heights and (less surprisingly) Liberty Island. It is also interesting to see how Manhattan pretty much drops off the map here – it seems there are lots of tweets sent from Manhattan, but by far the majority are sent in English.

Percentage of non-English tweets per 50m grid square (Coastline courtesy of ORNL)
Top Languages
So, having viewed the maps, you might now be thinking, ‘Where’s my [insert your language here]?’. Well, check out this list, the complete set of languages ranked by count. If your language still isn’t there then maybe you should go to New York and tweet something.
As you will see from the list, in common with London, English really dominates in the New York Twittersphere, making up almost 95% of all tweets sent. Spanish fares well in comparison to other languages, but still only makes up 2.7% of the entire dataset. Clearly, you wouldn’t expect the Twitter dataset to represent anything close to real-world interactions, but it would be interesting to hear from any New Yorkers (or linguists) about their interpretation of the rankings and volumes of tweets in each language.
Language Processing
Finally, a small word on the data processing front. Keen readers will be aware that in the course of conducting the last Twitter language analysis, we experienced a pesky problem with Tagalog. Not that I have a problem the language per se, but I refused to believe that it was the third most popular language in London. The issue was to do with a quirk of the Google Compact Language Detector, and specifically its treatment of ‘hahaha’s and ‘lolololol’s and the like. For this new analysis – working work with John Barratt and the wealth of data afforded to us by Trendsmap – we’ve increased the reliability of the detection, removing tweets less than 40 characters, @ replies and anything Trendsmap has already identified as spam. So long, Tagalog.
To be honesty, sina weibo is much more fun than tweeter, more and more people are using it.
Yes, we’d certainly love to get hold of the Weibo data!